Hierarchies are a great way to improve analysis in IBM Planning Analytics without adding additional dimensions to your cubes.
For example, your products may already roll up by product type, but you may also want to analyse those same products by manufacturing country, supplier or brand. Instead of manually maintaining multiple consolidation structures, you can automatically generate hierarchies using attributes that already exist within your dimension.
This is especially useful when dimensions are regularly updated from an ERP or source system, where manually maintaining hierarchies would quickly become time-consuming.
Creating Hierarchy’s using the “Create Hierarchy” shortcut . #
In Planning Analytics Workspace, there is a simple “Create Hierarchy” option available within the dimension editor by right clicking on the Dimension and selecting “Create Hierarchy”.
This automatically generates a basic hierarchy from an attribute.

The good news is that the same result can be achieved very easily using a TurboIntegrator (TI) process.
The advantage of building your own process is that you gain far more control over how the hierarchy is created and maintained.
What this process will do #
This process will:
- read a text attribute from a dimension
- create a new hierarchy
- automatically generate consolidations from the attribute values
- assign the leaf-level elements underneath them
Step 1 — Create a new TI process #
Create a new TurboIntegrator process with no data source.
We are only using the process to build metadata, so no source file or cube is required.
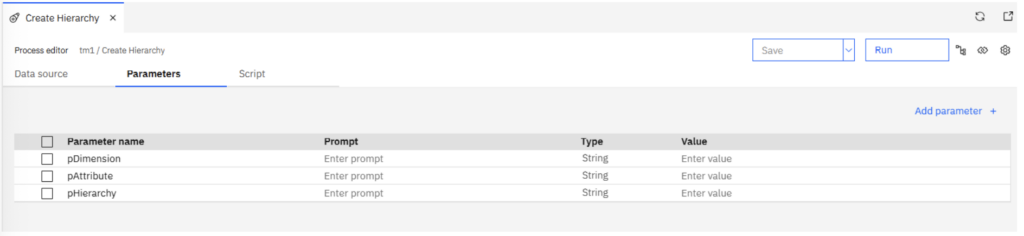
The process will use three parameters:
- Dimension Name
- Attribute Name
- Hierarchy Name
Step 2 — Add the Prolog code #
All of the logic sits within the Prolog tab of the process.
The script:
- checks the dimension exists
- creates or clears the hierarchy
- loops through the dimension elements
- reads the attribute values
- builds the hierarchy structure automatically
Paste the following code into the Prolog section:
# Check if the dimension exists, if it returns 0 it does not, then quit the process
if (DimensionExists( pDimension )= 0);
ProcessQuit;
endif;
# Set the name of the cube that stores the attributes for the dimension.
vAttributeCubeName = ‘}ElementAttributes_’ | pDimension ;
# Does the hierarchy exist in the dimension?
if (HierarchyExists( pDimension, pHierarchy )= 0);
HierarchyCreate( pDimension, pHierarchy );
else;
HierarchyDeleteAllElements( pDimension, pHierarchy );
endif;
# Set hierarchy sort order
HierarchySortOrder( pDimension, pHierarchy, ‘By Name’, ‘Ascending’, ‘By Name’, ‘Ascending’ );
# Create top level element
HierarchyElementInsertDirect( pDimension, pHierarchy, ”, ‘All ‘ | pHierarchy,’C’ );
# Count elements
vDimensionElementCount = DIMSIZ( pDimension );
vCount = 1 ;
# Loop through dimension
while (vCount <= vDimensionElementCount);
vElementName = DIMNM( pDimension, vCount );
vAttributeValue = ‘No Value’ ;
# Check leaf level
if (ElementLevel( pDimension, pDimension, vElementName )= 0);
# Check attribute has a value
if (CellGetS( vAttributeCubeName , vElementName, pAttribute) @<> ”);
vAttributeValue = CellGetS( vAttributeCubeName, vElementName , pAttribute );
# Create consolidation if required
if (HierarchyElementExists ( pDimension, pHierarchy, vAttributeValue ) = 0);
HierarchyElementInsertDirect ( pDimension, pHierarchy, ”, vAttributeValue, ‘C’ );
HierarchyElementComponentAddDirect(
pDimension,
pHierarchy,
‘All ‘ | pHierarchy,
vAttributeValue,
1.000000
);
endif;
# Add leaf element
HierarchyElementComponentAddDirect(
pDimension,
pHierarchy,
vAttributeValue,
vElementName,
1.000000
);
endif;
endif;
vCount = vCount + 1 ;
end;
Step 3 — Run the process #
When the process runs, you will be prompted to enter:
- the dimension name
- the attribute name
- the new hierarchy name
The following was entered as an example into the prompts:
- Dimension: x.reg and fleet number
- Attribute: Comp vehicle
- Hierarchy: Company Car
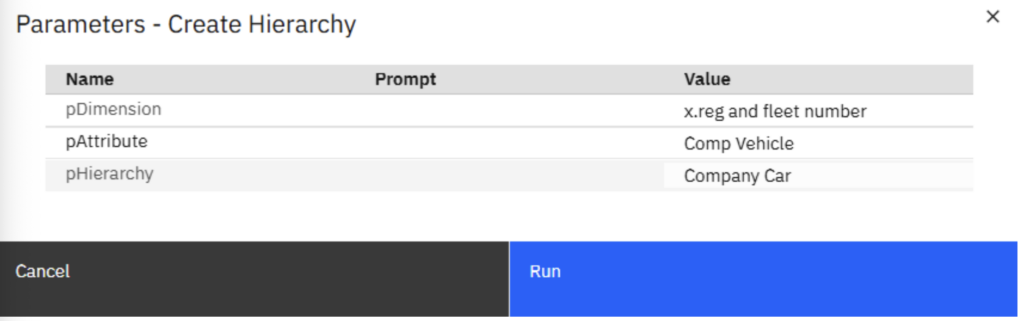
Click on ‘Run’ to Run the process, the process will complete when the ‘Process .. executed successfully’ message appears, as below:

Step 4 — Review the new hierarchy #
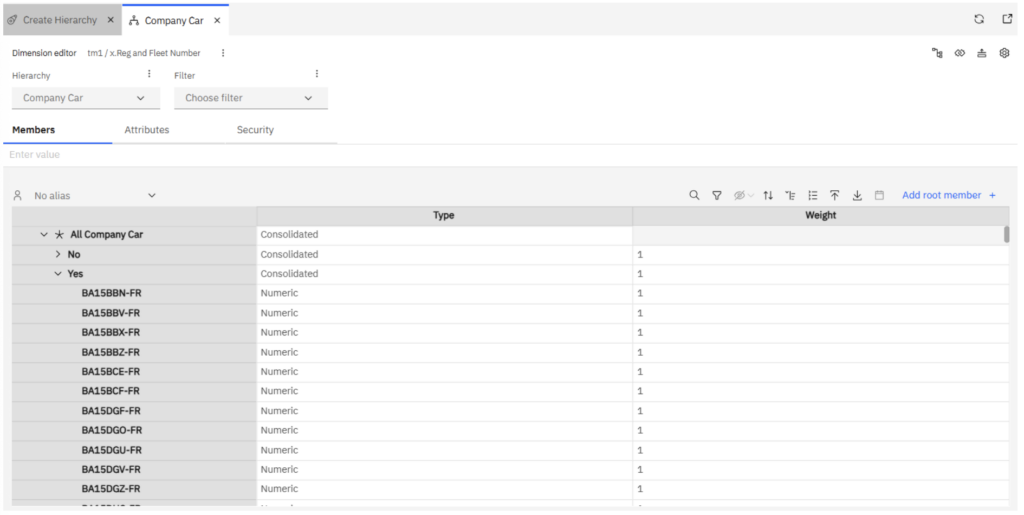
Once the process has completed, the new hierarchy, ‘Company Car’, will appear within the dimension.
The hierarchy structure will be built automatically from the attribute values.
This allows users to analyse the same products in multiple ways without changing the cube structure.
For example, users could now analyse:
- products by product type
- products by manufacturing country
- products by supplier
All using the same underlying Product dimension.
Things to be aware of. #
This process only includes leaf-level elements. Consolidated elements are ignored because Planning Analytics does not allow a consolidated element to become a child within another hierarchy structure.
Elements with blank attributes are also ignored. In many models this is perfectly acceptable, but you could extend the process to place blank values into an “Other” or “Unassigned” consolidation if required.
Because the hierarchy is generated automatically, it can easily be rebuilt whenever new products or attribute values are added from the source system.
Final thought #
Automatically generating hierarchies from attributes can save a significant amount of manual maintenance within IBM Planning Analytics, especially in models where dimensions are regularly updated from external systems.
It also gives users much more flexibility when analysing data, without adding unnecessary complexity to cube design.
If you would like help building automated hierarchies, improving metadata processes or reviewing your Planning Analytics model structure, feel free to talk to us.


