A Guide to Migrating to IBM Planning Analytics as a Service (PAaaS)
I have just completed the migration of a client from an old and unsupported version of TM1 to the latest PAaaS.
There is an adage that has followed me throughout my IT career, If I can do it, anyone can!
So, I undertook this task full of dread, expecting it to be difficult and frustrating in equal measure, but I was pleasantly surprised. We were on a tight deadline, and we hit some hurdles, some we were able to skirt around, and others left us flat on our faces.
The first thing that I needed to do was set up a GitHub account. Although GitHub is ubiquitous in the modern IT world, I had no familiarity with it at all. Immediately I felt as out of my depth as when my granddaughter talks about Taylor Swift. I know of Swift’s existence, but I couldn’t tell you a single thing about her.
At this point, I would have a chat with your IT colleagues. They may be using GitHub already in their software development and you may be able to piggy-back on their infrastructure and they might add you to the corporate enterprise environment. Or they might set you up. If not, setting up a GitHub account is straightforward, and you can have a free account.
The next bit was not so simple. The security for GitHub relies on public and private Secure Shell keys. This is safer than a password for moving stuff around the internet. You will need to generate these keys and you must have administration rights to your personal computer.
- Open the Windows Command screen as an Administrator.
- Change the directory to your local user directory e.g. C:\Users\<your username>
- Enter the command ssh-keygen -t ed25519.
- This will prompt for a name for the file e.g. SR_KEY
- Then a passphrase, (ignore this)
- Then a confirmation, just enter return.
- This will create 2 files ‘SR_KEY’ and ‘SR_KEY.pub’
- ‘SR_KEY.pub’ contains your public SSH key.
Then in GitHub on the ‘Settings’ option, select ‘Deploy keys’, give the key a name, and in the ‘Key’ box paste in the value from your ‘SR_Key.pub’ file and tick the ‘Allow write access’ option’.
I took the client’s TM1 database and ported it to a more modern version of the software. I used our development Planning Analytics on the Cloud environment, creating an empty database (from which I copied out the ‘} Clients. Dim’ and the} ClientGroup.cub’ files), then overlaid the TM1 database on top and then pasted back the ‘} Clients.dim’ and the} ClientGroup.cub’ files so that I’d have administrative access to the database.
The documentation says that you can keep users’ private views and subsets by creating a CloudD element in the ‘}CloudProperties’ dimension and then adding the name to the ‘}CloudProperties’ cube. This didn’t work for me, and we decided that the users would re-create their views and subsets on the PAaaS environment. This problem has now been fixed in 12.3.8.
At this point, we took the opportunity to knock some of the barnacles off the existing TM1 database. We removed cubes that were no longer used, extraneous copies of processes, and unused dimensions to create a streamlined database.
Now you’ve got your GitHub repository you can move objects such as dimensions, cubes, views, processes, chores, web sheets, control cubes, control dimensions, control processes, and files (available in the File Manager) are exported to a repository held in GitHub.
In the ‘Data and Modeller’ area of PAW you can create a new workbench, highlight the database that you wish to export the objects from, and click on the ‘Add objects to repository’ item in the menu. This will move cube structures but will not move the cube data. Also, it will move element attributes but will not move the values for the element’s attributes. The data needs to be exported to a CSV file and then use this file to populate the new database.
In your PaaaS environment, you create the database and then mirror what you’ve done on the export side and import these items from your GitHub repository.
This will give you a database that will give you the framework but you will be missing dimension attribute values and cube data.
You will need to export the element attribute details. I did this by creating a process that uses the }Dimensions control dimension. In the DATA section, I checked that the dimension wasn’t a Contol dimension and it wasn’t a hierarchy
if( SUBST( vDimension, 1, 1 ) @<> ‘}’ & SCAN( ‘:’, vDimension ) = 0);
and then checked to see if there was an Element Attributes cube where the values are stored
vAttributeCube = ‘}ElementAttributes_’ | vDimension ;
if( CubeExists( vAttributeCube ) = 1);
If there was an attributes cube, I created an MDX view
vMDX = ‘SELECT {[}ElementAttributes_’
| vDimension
| ‘].MEMBERS} on 0,’
| ‘{{[‘
| vDimension
| ‘].[‘
| vDimension
| ‘].MEMBERS}} ON 1 FROM [}ElementAttributes_’
| vDimension
| ‘]’
;
and called another process to read that view and output the values to a CSV file.
Exporting the cube data for one of the large cubes was the thing that caused me the most problems. There are limits to what you can upload. For the main P&L cube, there was a file of more than 200 MB. I was unable to process the file, so I then used the ‘SPLIT’ command on my Apple Mac to break each file into 3 files of about 70MB. On a Windows machine, you could use 7z or WINRAR. Importing the data was, on the other hand, very simple and the new File Manager interface is very easy to use. In hindsight, we could have looked at only porting over the historical data that was needed.
It also pays to read what has been deprecated in the new PAaaS environment. I was caught out using DIMIX, which we use to check whether an element exists. This function will still work in Planning Analytics for Excel. It doesn’t error in the TurboIntegrator editor, but it behaves inconsistently, which wasted hours of my time trying to work out why a process was erroring after 7,500 records on a value that had been processed happily earlier in the file. You should use the newer command DimensionElementExists, which makes a lot of sense. Also, there is no need any longer for the SaveDataAll command. They can be commented out and you don’t need to run background chores to do this any longer.
I was also caught out that the rules files for control cubes were not automatically ported over. These files were not huge, and I just opened the rule file in PAW and cut and pasted the rules over.
When I was working through the solution, I kept this map as a handy way of thinking about the overall system:
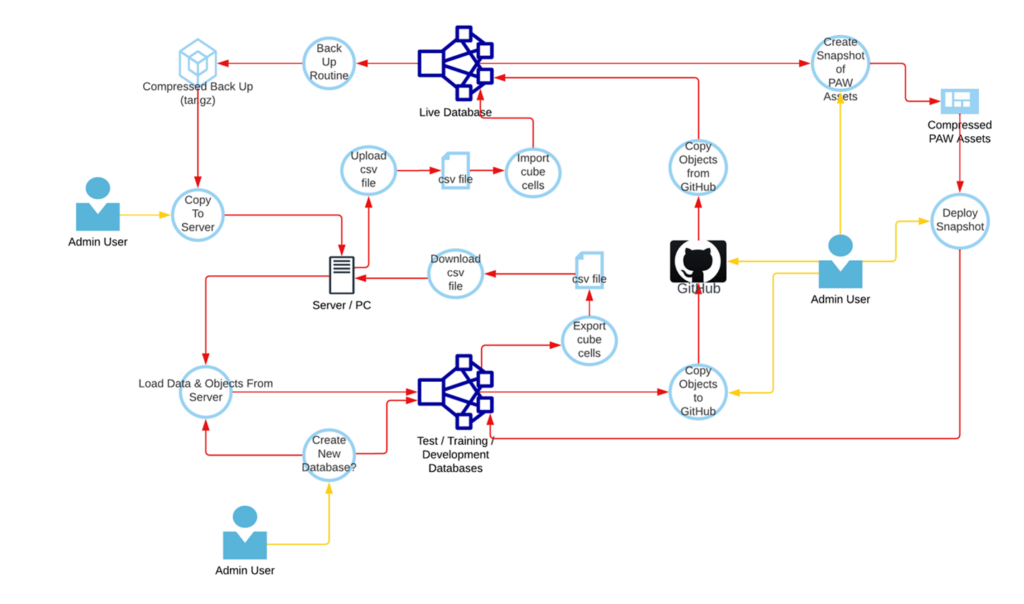
With the meta-data and data across the new environment, there is a lot to like. The system is easy to administer. You can set up backups for the database and these are kept for 28 days. I recommend that you download backups at strategic times, for example, after month-end, year-end, budgeting rounds, etc., and keep these on our company’s network. It’s very easy to reload these into a newly created database if you want to have a year-end database for audit purposes, or if you want to test a transformational process before running it in the live environment. It’s easy to create a training database for a new colleague to try things out on with real data, without doing any damage.
PAaaS frees up your IT colleagues. The software is kept up to date and can be administered from the PAW administration panel. You can invite new users and add them to security groups. You can increase the memory and disc space allocated to databases simply, with no technical knowledge. A modeler can control the security of cubes, dimensions, and elements from within the Data and models’ function.
In short, anyone with between 5 and 50 users should investigate moving to PAaaS as a cost-effective way of using the power of Planning Analytics with little or no burden on your IT colleagues.
There’s a free 30-day trial available which can be found here: https://register.saas.ibm.com/planningAnalytics/trial/aws
Things to do and consider:
Set up a GitHub account and create your Public & Private SSH keys.
Do I need to migrate all the cubes?
Do I need all the data in the cubes? What use is the budget information from 2013?
Do I need all the processes?
Check the deprecated commands. Some are obscure but others like DIMIX and SAVEDATAALL are in common use.
Let us know your thoughts here.
Chris Sands, Product Specialist – 25th March 2024